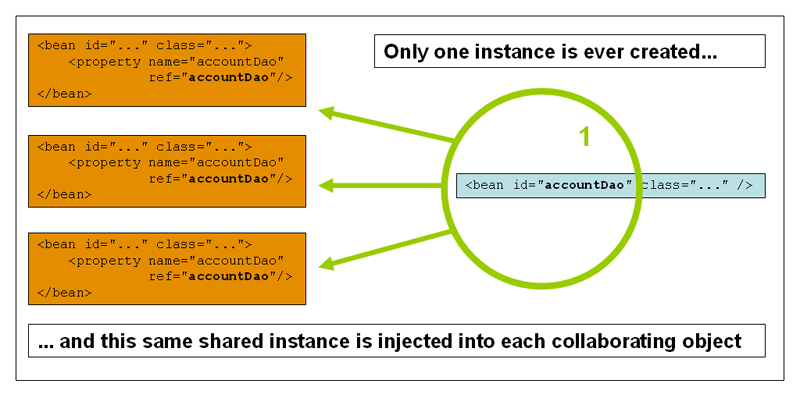
Singleton Scope
In this scope only one shared instance will be managed and any calls to the beans will result in giving the same bean to caller. That means, spring container creates only one bean (based on the definition of bean). This singleton is stored in a cache of such singletons and will be returned on subsequent requests. Usual singleton pattern mean you have one class per classloader but here we have one instance PER container. This is the default scope of all beans created in container. (example to follow after next section)
<bean id="emp" class="a.b.c.D" scope="singleton"/>is same as
<bean id="emp" class="a.b.c.D"/>
Prototype Scope
In this scope every time a new bean instance will be created when we request a bean from container (quite opposite to singleton). Usually use prototype beans for stateful beans and singletons for stateless beans.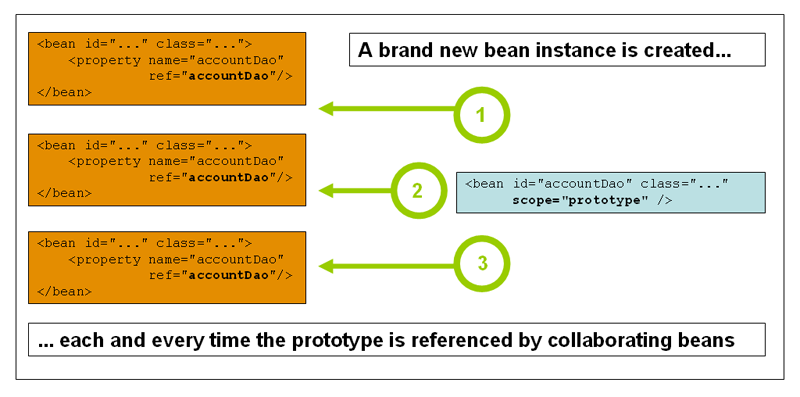
<bean id="emp" class="a.b.c.D" scope="prototype"/>you could think of prototype beans in analogous to java new operator. Moreover, spring container instantiates, configures and gives the prototype beans and then onwards it does not manage its complete life cycle, that means, although initialisation, call back methods are called on beans, no cleanup/destroy method will be called on prototype beans. Reason is, spring container is no longer managing them so its developer's responsibility to clean up prototype beans (like releasing database connection etc..) You could alternatively use "bean post processors" (we see later) to release resources hold by prototype beans as they hold beans those need to be cleaned up.
Singletons with Prototype Bean Dependencies
if a singleton bean has a dependency on a prototype bean then on the instantiating of singleton, prototype bean will also gets instantiated and that's the only instance dependency injected to that singleton. Further calls to singleton gives you a bean with originally injected prototype bean. To avoid this situation (like when you ask a singleton you are expecting injected prototype to be run) you must use lookup method injection (as specified in lesson 01)
In this example though Soldier is a prototype while instantiating Queen object it gets invoked and since then every time you ask for soldier in the queen object you get the same soldier object. But if you invoke soldier on its own, each time you get a brand new object. We work on request, session, global session while discussing spring mvc chapter
Creating Custom Scope
So far singleton scope, prototype scope serves for most of the situations. What if you want a custom scope such as, container should give you employee objects but for the first 3 times, you expect a same employee object and from the 4th invocation onwards you expect a new brand new employee object (such a silly example). Then you should write your own custom scope implementation (Remember: you can not override singleton/prototype scopes though).In order to define a custom scope you must implement "org.springframework.beans.factory.config.Scope" interface which has metods to retrieve object from scope and delete from scope as well.. If you are using BeanFactory then use beanFactory.registerScope("scopename", "scopeclass") but we can refer custom scopes from bean xml too. Below example configures custom scopes using "CustomScopeConfigurer", which takes a Map parameter called "scopes"

Customising Nature of a Bean
If you want to interact with bean life cycle, you should implement InitializingBean, DisaposableBean interfaces. methods like InitializingBean.afterPropertiesSet() & DisposableBean.destroy() method would be called to perform certain actions after initilization/before destruction of the beans instances. Usually it is suggested to use JSR-250's @PostConstruct and @PreDestroy annotations to achieve the same thing so that your code does not implement spring specific implementations. Similarly if you don't like to use JSR-250, considering implementing init-method, destroy-method attributes of <bean> elements to call method of a bean to call after initialise/pre destroy phases of beans. Internally spring uses BeanPostProcessors (more later) to process any call back interfaces. If you implement LifeCycle interface you could participate in startup and shutdown process as driven by container's life cycle.
In the following examples, it is shown to use all 3 ways to initialize (Implementing InitializingBean/DisposableBean, JSR 250 way, init-method) beans. It is useful sometimes to keep a method such as init() in all classes and mention it in <beans> element as below so that all bean's init() methods will be invoked as expected. Similarly default destroy method applicable to all beans in the container can also be specified. If any local bean has any init methods then they will be overwritten by <beans> element's init method calls.
<beans default-init-method="init" default-destroy-method="clean"> </beans>If for same bean you have all 3 ways configured with a different method name, then each configured method is executed in the following order (note: if the same method name is configured - for example,
init() for an initialization method - for more than one of these lifecycle mechanisms, that method is executed once). - Methods annotated with
@PostConstruct InitializingBean.afterPropertiesSet()- Custom
init()method
Destroy methods are called in the same order:
- Methods annotated with
@PreDestroy DisposableBean.destroy()- Custom
destroy()method

In this example same bean has 3 ways to initialise/destroy calls so output above explains the order. Try keep in scope="prototype" to the bean you created and you realise destroy method are not invoked (as said earlier, its developers job to clean up resources in case of prototype beans)
Added to that in above example, we are shutting down the container, in case of web application contexts (will see in mvc chapter) WebApplicationContexts closes application context gracefully but in non-web environments to shutdown the container gracefully, you register a shutdown hook with JVM. This hook ensures graceful shutdown and calling destroy method for all singleton beans. To do this you need to call ctx.registerShutdownHook(); where ctx is of type AbstractApplicationContext (cast your ApplicationContext to this as I did in above example)
Startup and Shutdown callbacks (TODO)
Aware of yourself with ApplicationContextAware & BeanNameAware
when ApplicationContext identifies a class (in its container) that implements then it provides a reference to that ApplicationContext. So with this reference you could programatically retrieve beans and perform all operations an application context would do. But this not a good practice as your code is tightly coupled with spring framework. In Spring 2.5 due to autowiring by type (autowire="byType") allows to retrieve ApplicationContext in to your constructor arguments and bean properties. Similarly when container sees a bean that implements BeanNameAware interface, then container provides the name of the bean to it. The callback is invoked after population of normal bean properties but that should be before an initialisation or a custom init-method. Let us see this with an example:

- org.springframework.context.annotation.internalConfigurationAnnotationProcessor
- org.springframework.context.annotation.internalAutowiredAnnotationProcessor
- org.springframework.context.annotation.internalRequiredAnnotationProcessor
- org.springframework.context.annotation.internalCommonAnnotationProcessor
Container Extension Points
if you want to implement your own bean instantiation method (or override the existing method) then consider implementing one of the BeanPostProcessor interfaces. Container calls these call back interfaces after bean instantiating/configuration/intializing the bean. That means you could plug one or more BeanPostProcessor implementation (using ordered attribute) as all these BeanPostProcessors implement Ordered interface. You should this as well if you write your own BeanPostProcessor. BeanPostProcessors operate on bean instances (Spring IOC instantiates bean then BPP do their work). These BPP are scoped per container. To actually change bean definition altogether consider using BeanFactoryPostProcessor (next section). If any class is implementing BPP then call back methods will be called on beans BEFORE calling any init-method (or custom bean initialization method). Container detects and beans defined in configuration meta data that are implementing BPP. ApplicationContext registers them as "post-processors" so that they can be called later upon bean creation.
classes implementing BPP are kind of specially treated by container. They are instantiated along with beans they reference directly as part of special phase of the startup. Since AOP auto-proxying (dont worry we see this in next chapter too) is implemented as a
classes implementing BPP are kind of specially treated by container. They are instantiated along with beans they reference directly as part of special phase of the startup. Since AOP auto-proxying (dont worry we see this in next chapter too) is implemented as a
BeanPostProcessor itself, so neither BeanPostProcessors nor the beans they reference directly are eligible for auto-proxying, and thus do not have aspects woven into them. Following example illustrates the concept of BPP 
From this its clear that BPP can completely change the bean instance and customise bean instantiation process, We did nt even give id attribute to BPP as we never wanted to call them using getBean method. Its all containers job to register them and provide call backs when needed. "RequiredAnnotationBeanPostProcessor" is a special BPP ships with spring allows us to JavaBean properties on beans that are marked with an (arbitrary) annotation are actually (configured to be) dependency-injected with a value.
The next post processors in the series are BeanFactoryPostProcessors (BFPP) and their semantics is as same as BPP except that they work on "bean configuration meta data", Container allows BFPP to read configuration meta data and allows to change it before any bean (other than BFPP) instantiation happens. Just like BPP, BFPP as well follows Ordered Interface and we can create multiple BFPP. I hope its clear that if you want to change Bean Instances, use BPP. Even BFPP allows that better not use it as it conflicts default life cycle. Just like BPP, BFPP works PER container only. Usually BPP, BFPP are not mean to be lazy initialised. Even if you set defauly-lazy-init to "true" that will be ignored on <beans> element for BFPP, BPPs. Spring provides few out of the box BFPP called as PropertyPlaceholderConfigurer and PropertyOverrideConfigurer. The primary objectives of these BFPP are to externalise property values to the bean definition using standard java Properties format and PropertyOverrideConfigurer like PropertyPlaceholderConfigurer only but unlike the latter, the original definitions can have default values or no values at all for bean properties. If an overriding Properties file does not have an entry for a certain bean property, the default context definition is used. In the following example we see both of them in detail...

Custom Instantiation Logic with FactoryBean implementations
In case if your bean instantiation logic is quite complex to express in XML you could implement FactoryBean and customise bean instantiation there itself.. "FactoryBean" interface comes with handy method to return a new bean object from factory. Its all managed by container but you need to take care of instantiation+Setting dependencies of the bean, you can always refer factory bean by prefixing it with an ampersand like shown in the below example.

No comments:
Post a Comment